Blackbox Exporter
Information about the special fork of the Blackbox Exporter used for the Science Mesh project
This section contains details about automated health monitoring in the Science Mesh project.
Note that monitoring is not a replacement of your standard monitoring of your EFSS installation, it is just an additional part to collect information relevant for the Science Mesh.
The Science Mesh in its entirety can only work if all of its participating sites with their respective services function properly. To ensure this in an automated way, all services are constantly being monitored and checked for their health status through various services running as part of the Central Component.
The two main components used for health monitoring are Prometheus and the Blackbox Exporter. They are both automatically configured and controlled by Mentix, the main service of the Central Component. Below diagram shows how these services are connected:
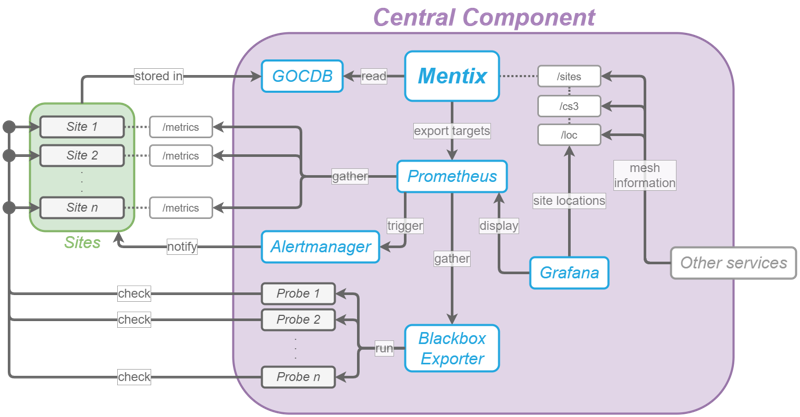
There are many reasons why we perform health checking from the outside: First of all, these checks do what a regular user would do, and it is thus important that the checks succeed when run from an external source. Many problems arise due to firewalls or misconfigured ingress servers.
Furthermore, having all checks in a central place makes adding and modifying checks a lot easier. It also ensures that the same checks are run for every site at all times. Last but not least, it gives all participating sites confidence in the reliability and meaningfulness of these checks and their results.
The health monitoring doesn’t impose any assumptions on the EFSS system a site uses. The underlying system is, however, indirectly tested through the CS3 APIs and the IOP: If there are issues with your EFSS, these will very likely result in failing checks.
Prometheus is used to gather various metrics from each site. This includes the total number of users, the number of user groups and the amount of storage used. These metrics are exposed through the Reva IOP (or any protocol-compatible service), which means that its metrics HTTP endpoint needs to be accessible from the outside.
Furthermore, Prometheus will also periodically pull metrics from the Blackbox Exporter (BBE for short), which runs in parallel to Prometheus. This in return causes the BBE to run active health checks on every site and its respective services, as explained below.
To monitor the health of each site in the Science Mesh, a custom fork of the Blackbox Exporter for Prometheus is used. Put simply, the BBE runs a so-called prober to perform a certain check on a provided target when called via a special URL. More technical details about this version of the BBE are available in a separate document.
The general workflow of this active health checking roughly looks like this:
Currently, only a small number of checks is performed during health monitoring. Below is a list of all checks and what is necessary to pass them:
| Check name | Description | Passing criteria | Critical |
|---|---|---|---|
http_ping | Checks whether the IOP can be reached via HTTP | IOP URL must be properly configured and reachable from the outside | Yes |
iop_login | Checks whether logging in to the IOP gateway is possible | IOP gRPC port must be properly configured and reachable from the outside; a user with credentials test/testpass must be available (this is only temporary and will change in the future) | Yes |
All critical tests must be passed for a site to be considered Healthy. Failing uncritical tests will only cause a site to go into Warning state.
Note: These tests are only temporary. More tests will be added in the future.
All above tests are performed on endpoints provided through the CS3 APIs. This means that you will need to make your CS3 APIs interface (usually the Reva IOP) externally accessible.
A user with username test must be present in Reva. Credentials for the
account are securely stored in the Central Database, they are configured
per site in the accounts panel (under “Sites settings”). The site
administrator needs to have access to site settings in the Central Database
for this agenda to be visible. Configure the credentials of the test user
both in the Central Database as well as your EFSS.
Information about the special fork of the Blackbox Exporter used for the Science Mesh project